Esta entrada es parte de un conjunto de posts extraídos directamente del artículo ya escrito que versa sobre este tema, el cual es completamente accesible y se puede leer en la siguiente dirección: https://s.javinator9889.com/rg-docker
Para un vistazo completo, detallado, con referencias y citas se recomienda encarecidamente leer dicho artículo.
La era tecnológica ha avanzado en los últimos años a pasos agigantados, y las demandas del sector han crecido junto a ella. No hace más de 200 años se “descubría” la electricidad; hace 90 años nacía la primera computadora básica capaz de realizar operaciones aritméticas; hace 70 años nacía el transistor que sustituyó las válvulas de vacío y desde entonces, el crecimiento ha sido exponencial.
Comparativa de una válvula de vacío (izquierda) frente a un transistor (centro) y un circuito integrado (derecha).
Otro de los ejemplos de tecnologías que han crecido exponencialmente son los dispositivos de almacenamiento, donde no hacía más de 20 años las capacidades máximas se estimaban en torno a los MB (megabytes) y ahora se hablan de EB (exabytes). Esta evolución es muy representativa también a nivel económico, ya que el coste del almacenamiento ha ido bajando a medida pasaba el tiempo, así como el espacio físico que ocupan los dispositivos:
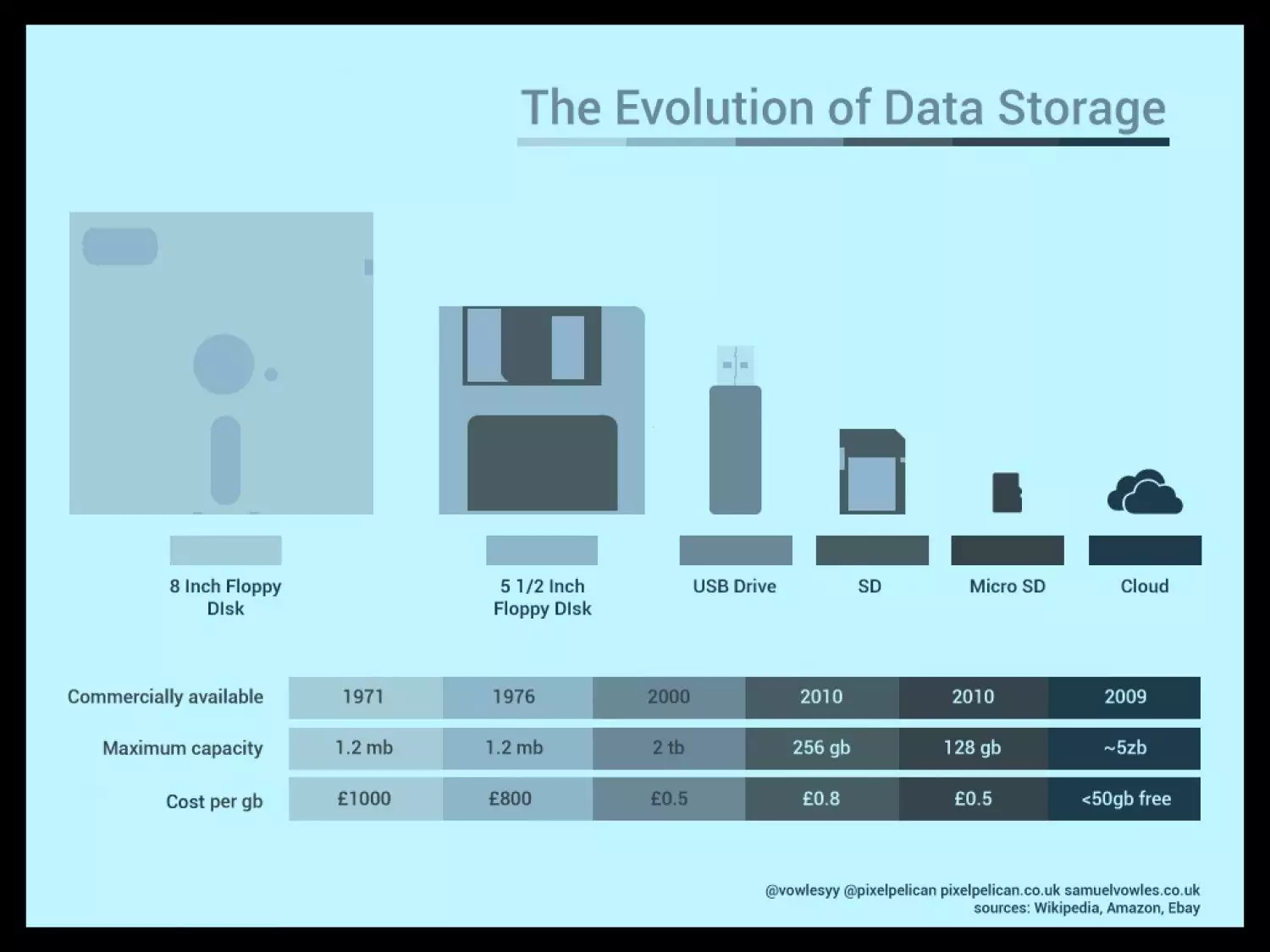
Evolución del espacio de almacenamiento en términos económicos y cuantitativos. Fuente: WeComputingTech
Finalmente, el gran salto tecnológico se ha producido con la aparición de Internet y cuando las comunicaciones ya no eran únicamente personales sino entre dispositivos. En relación con el punto anterior, la aparición de Internet ha permitido descentralizar el espacio donde ya el usuario no guarda su información en su equipo personal sino en un clúster de servidores distribuidos a nivel mundial al cual accede, de forma simultánea, desde Internet y desde cualquier dispositivo. Así, lo que comenzó como una red de conexión de unos pocos usuarios ha acabado convirtiéndose en la red global que todos usamos y que conecta más de 4 billones de dispositivos:
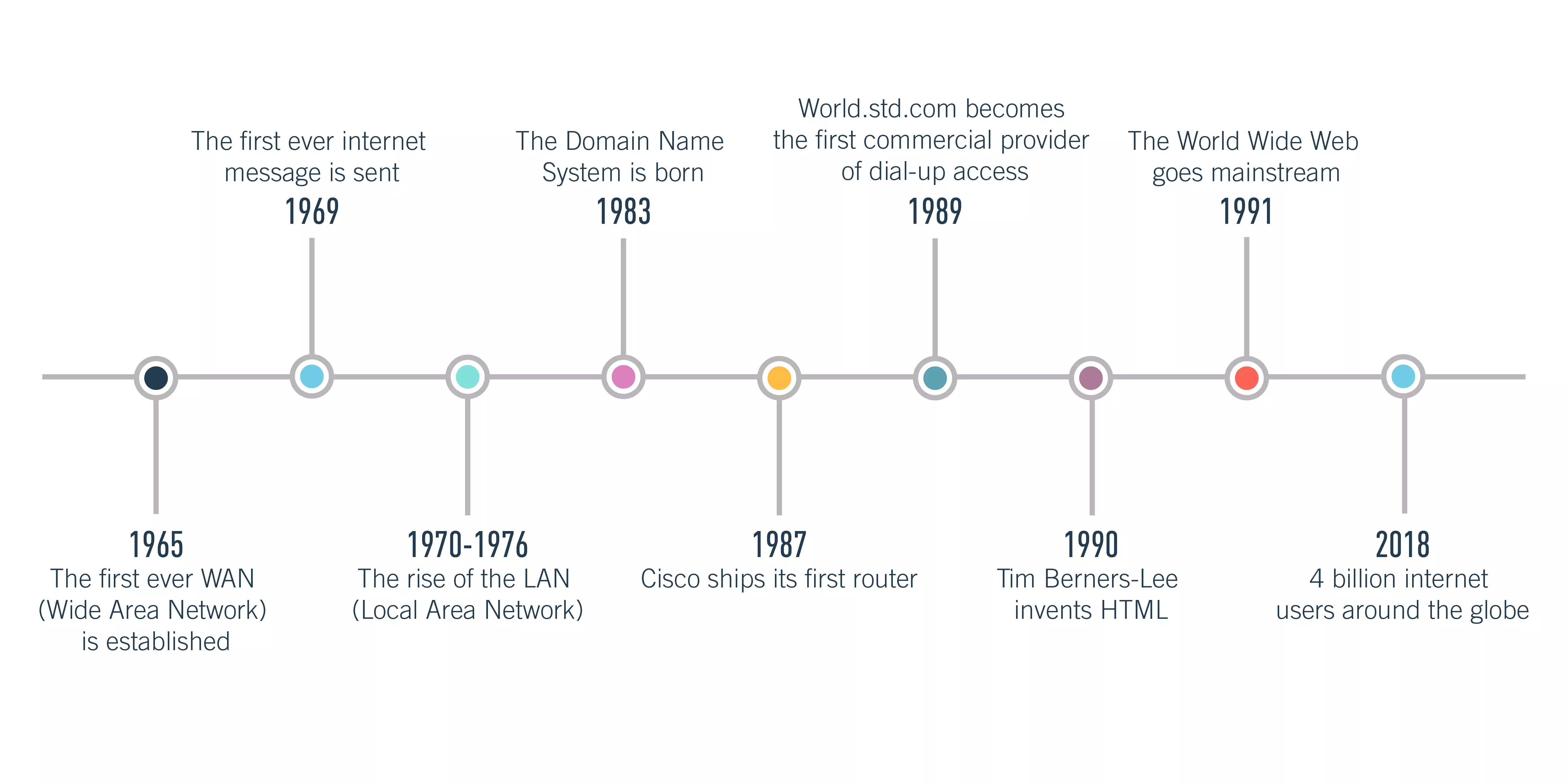
Evolución de Internet a lo largo del tiempo, hasta llegar a hoy. Fuente: CareerFoundry
El problema de esto es evidente: con una mayor capacidad de cómputo, con más opciones de comunicación y con más posibilidad de almacenar datos, los requisitos de las aplicaciones van creciendo y creciendo y cada vez son más complejos de satisfacer, no necesariamente a nivel hardware (que por lo general suele acompañar) sino a nivel software. Como las aplicaciones se orientan a los usuarios es necesario añadir capas de abstracción (como el sistema operativo) para facilitar la labor a la persona. Sin embargo, cada capa nueva que se añade dificulta las tareas de despliegue y mantenimiento dado que existe una gran variedad de combinaciones hardware y cada una puede estar con un sistema operativo distinto.
Por otra parte, la extensión de dependencias y posible incompatibilidad entre ellas suele desembocar en el uso de versiones desactualizadas de una librería ya que tendríamos “paquetes rotos”. Esto es tan común que tiene hasta su propio término coloquial “dependency hell”. Contar con dependencias obsoletas que ya han cumplido con su ciclo de vida software conlleva unas implicaciones de seguridad bastante severas:
Si un software no ha mejorado a lo largo del tiempo, existe una malicia humana que puede aprovecharse de distintos exploits existentes y comprometan nuestra aplicación.
Un software no actualizado puede tener implicaciones directas sobre el sistema en que se ejecuta, pudiendo producir fallos en el mismo. Esto se debe principalmente a que el hardware sigue mejorando y creciendo y un software antiguo puede presentar bugs en dispositivos modernos que no presentaría en antiguos.
Un software no actualizado puede comprometer otros elementos del sistema en que se ejecuta. Por ejemplo, una aplicación ‘A’ hace uso de dicho software y una aplicación ‘B’ también. Sin embargo, la última aplicación se ha diseñado para trabajar con la última versión del software pero la aplicación ‘A’ solo puede funcionar con una versión antigua e insegura. Por consiguiente, pese a que la aplicación ‘B’ funcionaría correctamente el hecho de usar una versión antigua e insegura del software compromete directamente al sistema y a la aplicación.
Es por eso que existen alternativas como chroot y máquinas virtuales
para subsanar estos problemas. Sin embargo, en los últimos años ha
aparecido una herramienta muy sonada y con gran éxito: Docker y los
contenedores.
¿Qué es Docker?
Docker es una plataforma abierta diseñada para el desarrollo, despliegue y ejecución de aplicaciones. La idea fundamental que reside detrás de Docker es la de separar la infraestructura de las aplicaciones de manera que se pueda entregar el software rápidamente.
Por debajo, Docker ofrece una plataforma que otorga la habilidad de empaquetar y ejecutar las aplicaciones en un entorno aislado llamado “contenedor” (container). Entre otras características, un contenedor permite ejecutar una aplicación de forma segura sobre el host en cuestión. La pregunta que surge es, ¿qué es un contenedor?
Contenedores
Un contenedor es una unidad estándar software que empaqueta código y todas sus dependencias de manera que la aplicación se ejecuta rápidamente y de forma fiable bajo múltiples entornos de ejecución. Una imagen Docker es un paquete ligero, independiente y ejecutable que incluye absolutamente todo lo necesario para poder ejecutar una aplicación: desde el código en sí hasta el runtime, herramientas del sistema, librerías y configuraciones.
Durante la ejecución, una imagen se convierte en un contenedor que se ejecuta sobre la máquina Docker (Docker Engine), la cual se encuentra disponible en entornos Linux y Windows.
Al fin y al cabo, los contenedores nos aseguran que una aplicación que hemos desarrollado se va a ejecutar de la misma manera en una máquina u otra. El uso del motor Docker permite ejecutar múltiples contenedores sobre un mismo anfitrión sin añadir demasiada carga en el sistema e indiferentemente de la infraestructura que exista por debajo:
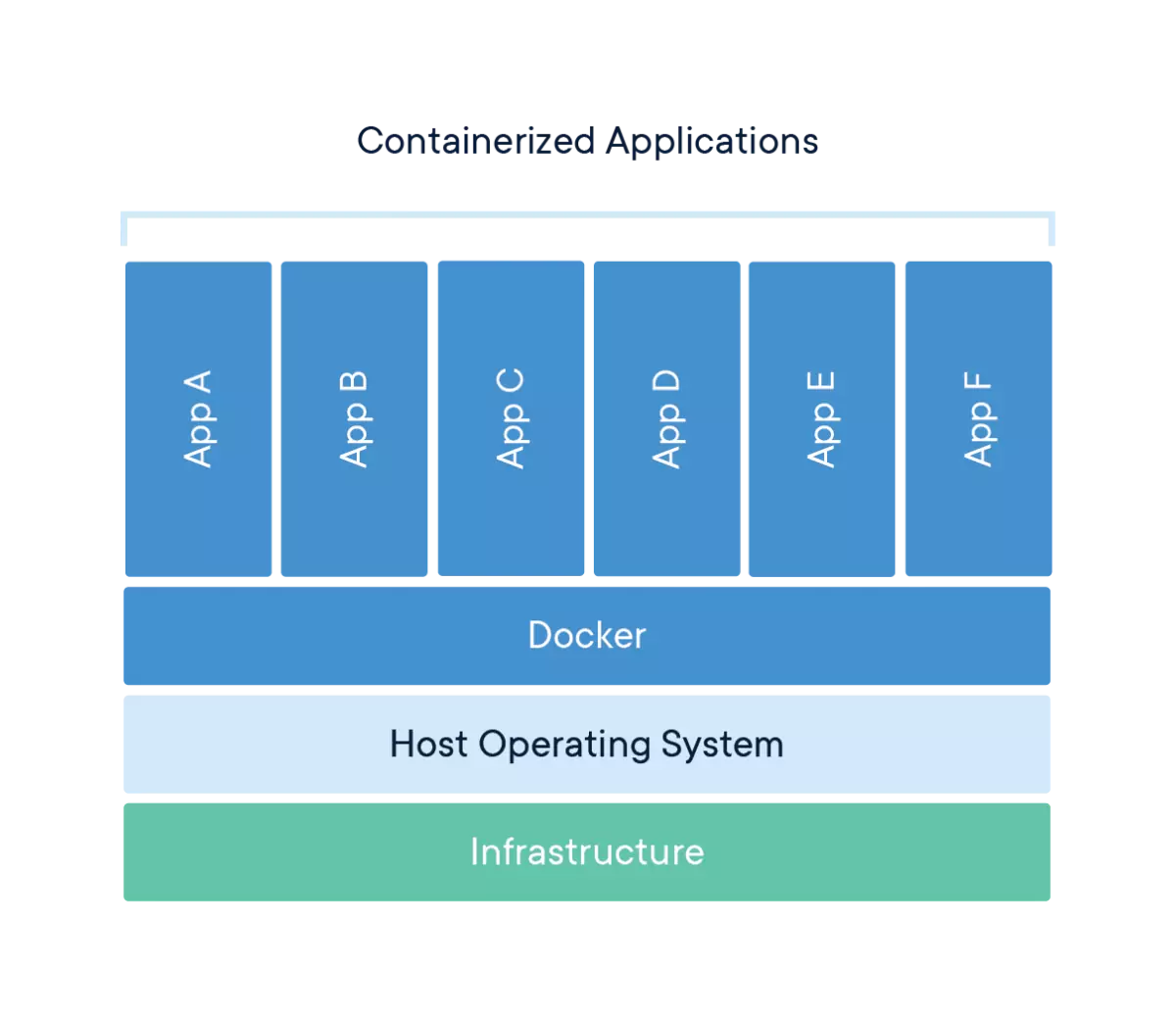
Distribución de los contenedores sobre el motor de ejecución de Docker. Fuente: Docker
La distribución de los contenedores mostrada en la figura anterior puede parecerse mucho a la distribución que tendríamos en una máquina virtual. Sin embargo, hay varias características que lo distinguen principalmente:
Un contenedor se ejecuta directamente sobre la máquina anfitriona, mientras que una máquina virtual requiere de un hipervisor.
Un contenedor es una abstracción de la capa de aplicación que encapsula el código y las dependencias juntas, mientras que una máquina virtual es una abstracción de una capa física hardware.
Un contenedor comparte el kernel con el sistema operativo anfitrión, por lo que tiene un gran rendimiento; mientras, una máquina virtual ejecutará su propio kernel sobre el hipervisor del sistema operativo anfitrión.
El espacio que necesita un contenedor es muy pequeño en comparación con el de una máquina virtual, que engloba y encapsula un sistema operativo al completo.
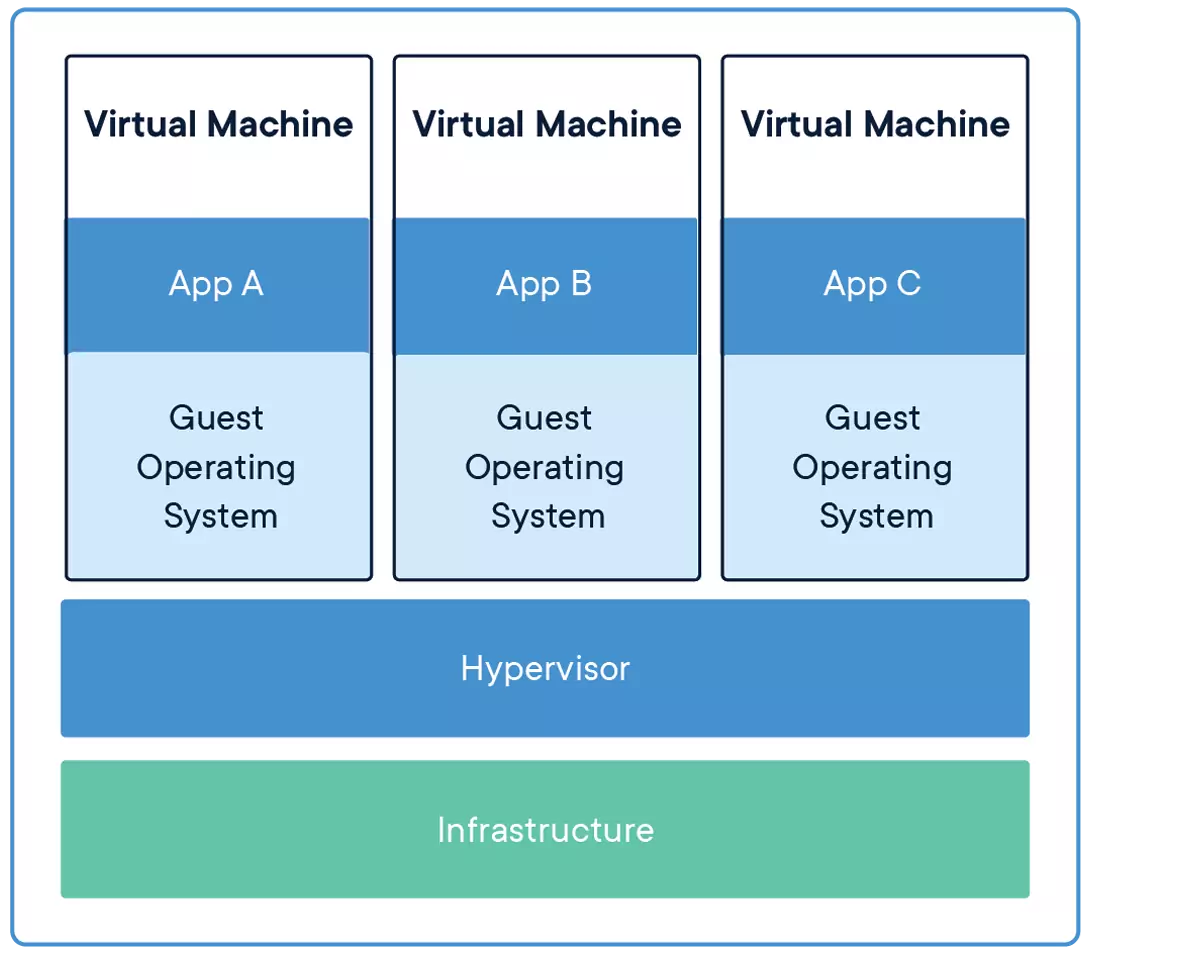
Capas de abstracción de una máquina virtual sobre una máquina anfitriona. Fuente: Docker
En la figura anterior se puede apreciar cómo una máquina virtual añade muchas más capas de abstracción que ralentizan el rendimiento. Sin embargo, esto no quiere decir que sean una mala alternativa: la realidad es que se combinan las dos para obtener una gran flexibilidad para desplegar aplicaciones – contenedores cuando se quiere ejecutar algo directamente sobre el anfitrión; máquinas virtuales para emular hardware y que ejecuten en su interior contenedores para ejecutar aplicaciones fácilmente.
La evolución y constante mantenimiento de los contenedores ha generado lo que se conoce como estándar de la industria “containerd”. Este estándar define claramente qué arquitectura debe tener un contenedor por debajo y está en constante evolución a medida que la industria crece y madura.
Además, la especificación anterior ha pasado de ser un mero estándar a una aplicación en sí de gestión y orquestación de contenedores, permitiendo que aplicaciones distintas de Docker hagan uso de la arquitectura basada en contenedores aprovechando la OCI: Open Container Initiative
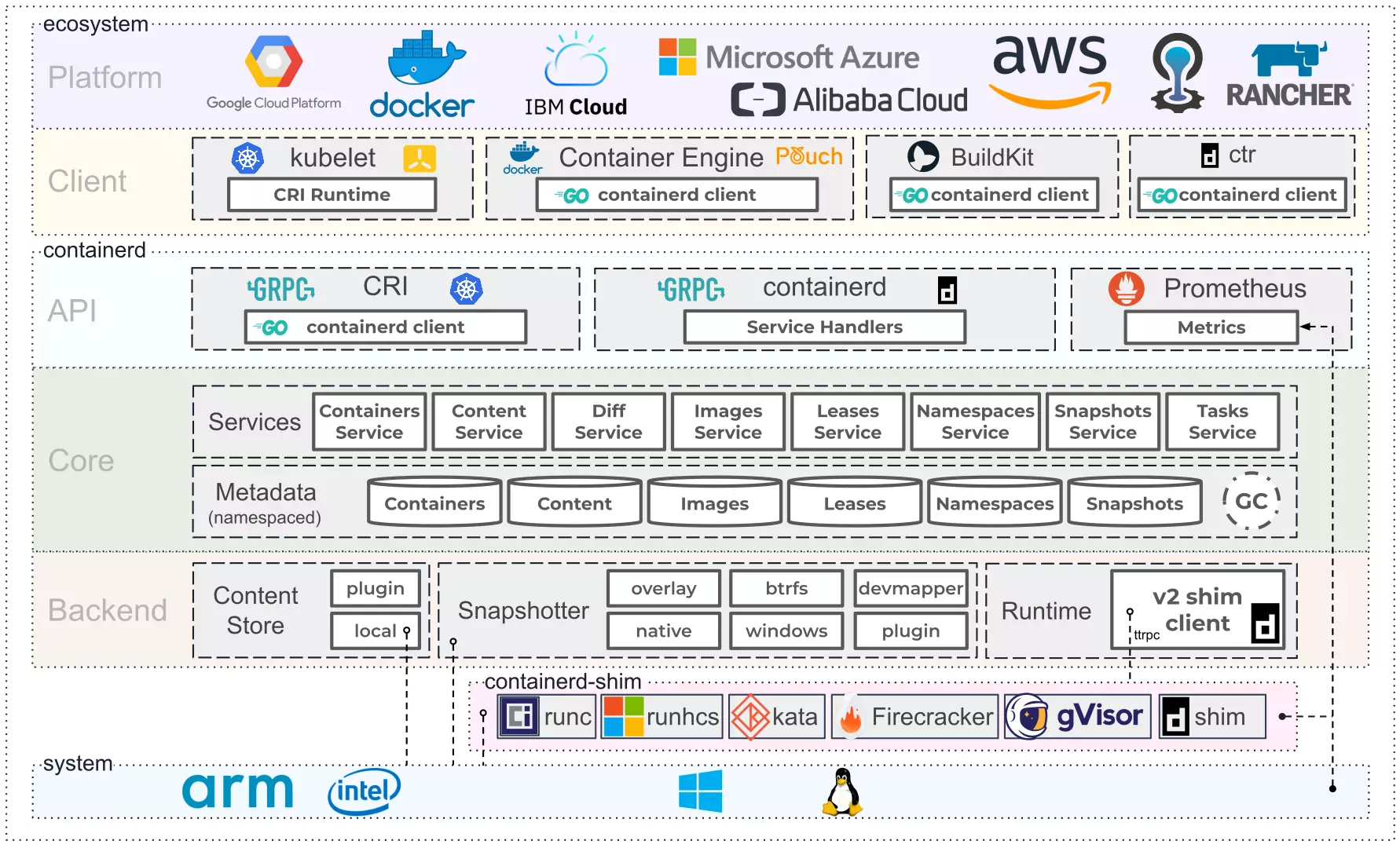
Entorno de ejecución de containerd basado en runC de la OCI. Fuente: Containerd
Docker Engine
El motor de ejecución de Docker establece la arquitectura de ejecución de facto que es utilizable desde distintas distribuciones Linux y servidores Windows.
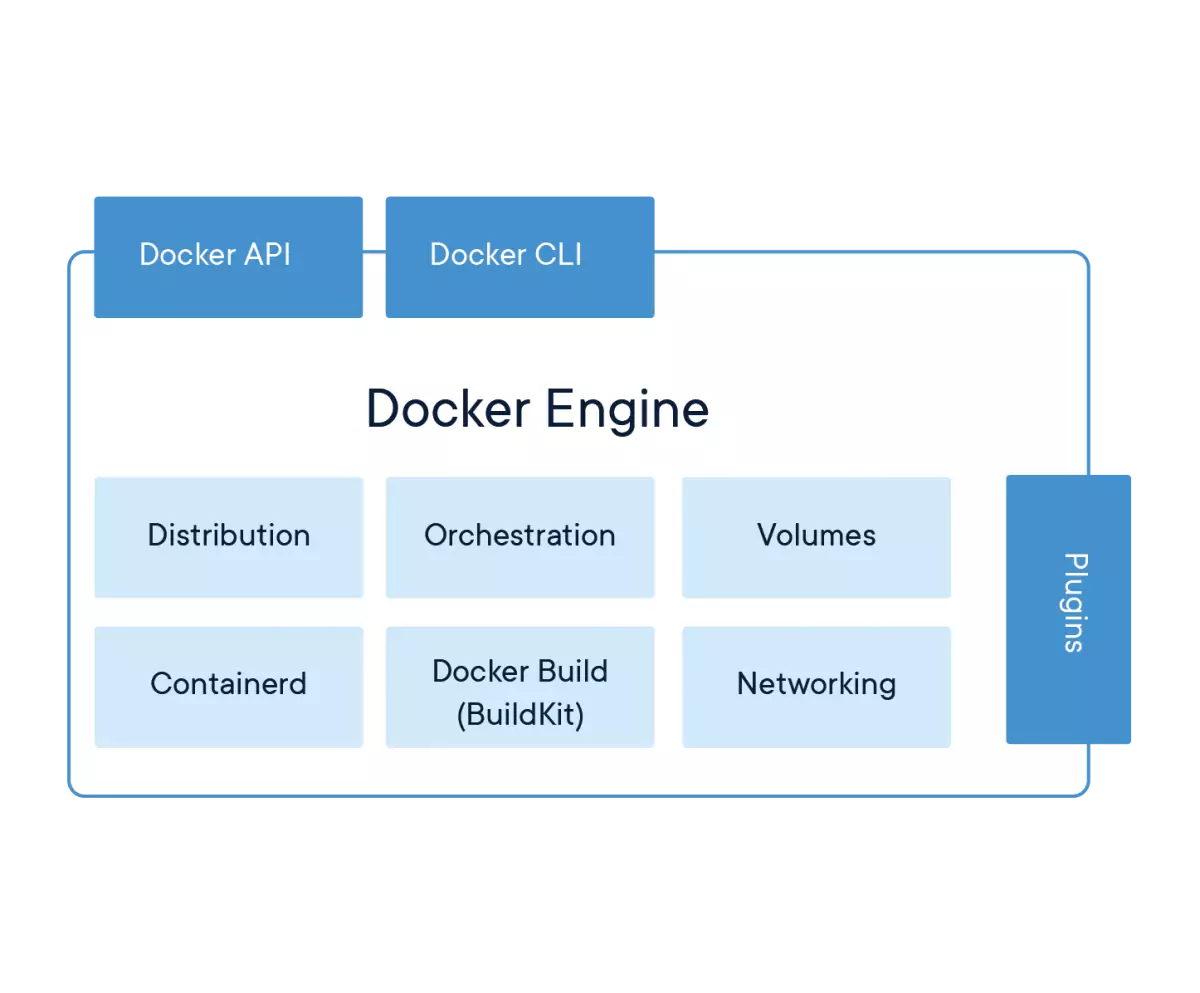
Arquitectura del entorno de ejecución de Docker. Fuente: Docker
El motor de ejecución de Docker se compone de una gran cantidad de elementos que encapsulan de forma uniforme multitud de aptitudes de un sistema operativo o una aplicación. Este entorno de ejecución sin embargo es complejo ya que engloba multitud de elementos físicos, como pueden ser las interfaces de red y los volúmenes.
Esto resulta fundamental ya que los contenedores Docker no tienen ni que confiar en la red del anfitrión: tienen su propio stack de red para realizar las comunicaciones que necesiten. Con el motor de ejecución de Docker se busca solventar esos problemas “dependency hell” que se han comentado anteriormente y la situación de “en mi equipo funciona”.
De los elementos del motor Docker mostrados anteriormente, se tiene que son:
Distribution: la distribución Linux en la que se basa el contenedor. Actualmente, Docker solo permite ejecutar contenedores basados en Linux.
Orchestration: cuando hay múltiples contenedores, la orquestación es el proceso por el cual el motor de ejecución de Docker gestiona y maneja qué contenedores se ejecutan, cómo se comunican, cuáles hay que crear nuevos y cuáles eliminar. Es de las partes más complejas que existen en el mundo de los contenedores y ha evolucionado a clústers mucho más completos (y complejos) como Kubernetes o Docker Swarm.
Volumes: los volúmenes (conjuntos de datos) que se manejan en los contenedores. Debido a su arquitectura cerrada, los datos que genera un contenedor solo están visibles para ese contenedor mientras este esté en ejecución. Cuando finalice, todos los datos no persistentes son eliminados.
Containerd: el estándar y cliente de ejecución y manejo de los contenedores a muy bajo nivel.
Docker Build (BuildKit): herramienta de libre distribución que transforma los ficheros
Dockerfileen imágenes Docker, listas para ser usadas y distribuídas.Networking: stack de red completo que se pone a disposición de cada contenedor Docker. Cada aplicación puede crear su propio dispositivo de red que cumpla con los requisitos que necesita. Existen varios tipos de adaptadores: bridge, NAT y host. El primero se emplea para realizar comunicaciones a través de red entre distintos contenedores; el segundo para realizar comunicaciones con el exterior mediante una conexión de red completamente independiente a la del anfitrión; la tercera para compartir la interfaz de red del anfitrión con el contenedor, como si fuese una aplicación interna.
Con todo lo anterior, una aplicación puede ejecutarse muy fácilmente en cualquier equipo que integre el motor de ejecución de Docker.
Real–life usages
Desde que nació en 2013, Docker ha ido creciendo y con ello las aplicaciones directas que ha encontrado en el mercado.
Sandboxing
Una de las principales ventajas que otorgó Docker desde su nacimiento fue el de aislar las aplicaciones entre sí y, por consiguiente, ofrecer un entorno de “caja de arena” (sandbox) en donde ejecutar nuestras aplicaciones (o aplicaciones inseguras) con cierta confianza.
Es cierto que esta característica ya estaba asentada con las máquinas virtuales, y funcionaba correctamente y de forma efectiva. Sin embargo, el tiempo de despliegue y lentitud de una máquina virtual hacía que usarlas para este propósito fuese costoso y no resultase interesante.
Con los contenedores se puede tener un entorno aislado que funciona igual de rápido que una aplicación nativa con unos tiempos de despliegue y uso de recursos limitado. Como se ha visto anteriormente, el motor de ejecución de Docker tiene el control sobre un montón de componentes virtuales y reales que permiten, entre otros, limitar y restringir el acceso a los recursos hardware del dispositivo. Bajo esta premisa, un contenedor puede usar solo cierta cantidad de CPU, RAM o red y que cambie en tiempo de ejecución.
Portabilidad
Otra de las características fundamentales de los contenedores es la capacidad de encapsular un software y todas sus dependencias. Esto convierte a los contenedores en una gran solución portable: sabemos que si una aplicación funciona en Docker en un equipo Linux, funcionará en Docker de otro equipo Linux exactamente igual, sin necesidad de realizar ningún cambio e indiferentemente de la distribución.
Con la llegada de WSL2, el kernel de Linux se introdujo al completo dentro de las máquinas Windows 10, permitiendo que Docker se pudiera ejecutar de “forma nativa”. Con esto, la limitación anterior se elimina y los contenedores diseñados para Linux funcionarán también en Windows.
Esto ha tenido una repercusión directa con el auge de los sistemas basados en la nube, los cuales a veces resultaban complejos y tediosos. Con los contenedores, una aplicación que un desarrollador ejecuta on-premise en su equipo puede ser fácilmente desplegada a un entorno cloud sin necesidad de preocuparse si cumple los requisitos o instala las dependencias. La única restricción es que el entorno cloud al que se mueva soporte Docker.
Arquitectura de composición
Una gran mayoría de aplicaciones que se ejecutan actualmente están ejecutándose sobre una pila de aplicaciones: servidor web, base de datos, caché en memoria, gestión de logs, etc. La pregunta es, ¿qué sucedería si se encapsula cada una de esas aplicaciones en un contenedor?
Así nace la arquitectura de microservicios, tan popular y estandarizada hoy en día. Un microservicio define un elemento único de una aplicación (que puede ser usado entre $1 \dots n$ veces) el cual acelera y facilita las labores de desarrollo de una aplicación. Entre otras ventajas, un microservicio puede ser actualizado, reemplazado, eliminado o modificado sin afectar al resto de microservicios que componen una aplicación. Esta alternativa se ha asentado como la solución ideal a las aplicaciones monolíticas monstruosas, que lo engloban todo (como XAMPP) ya que han demostrado ser mucho más fáciles de mantener y desarrollar.
Escalado y orquestación
Aprovechando la arquitectura de microservicios y contenedores, existen técnicas de escalado y orquestación automáticas basadas en Docker y contenedores.
De esta manera, en picos de conexión se despliegan automáticamente más contenedores que gestionan entre ellos las peticiones entrantes y salientes. Cuando las solicitudes bajan, los contenedores en deshuso desaparecen para dejar de usar recursos.
Entre las herramientas más sonadas para la gestión de contenedores está Kubernetes, desarrollado por Google. La idea de orquestación nace a raíz de esta empresa que empieza a invertir cantidades millonarias de dinero en contenedores porque le ve un nuevo potencial: las comunicaciones vía Internet de los contenedores. Hasta ahora solo hemos visto un modelo de arquitectura: un cliente Docker que ejecuta uno o varios contenedores. Sin embargo, con la aparición de los microservicios y la orquestación, y dadas las características de red de los contenedores, se abre la posibilidad de que múltiples clientes Docker en máquinas físicamente distintas puedan estar ejecutándose de forma simultánea y compartiendo datos entre ellos fácilmente.
Debido a las capas de aislamiento de Docker, esta comunicación no es sencilla: no sirve con comunicar dos direcciones IP. Sin embargo, utilizando un motor de Docker distribuído se pueden realizar las conexiones como si de una LAN se tratase, cuando en realidad se está usando una red overlay:
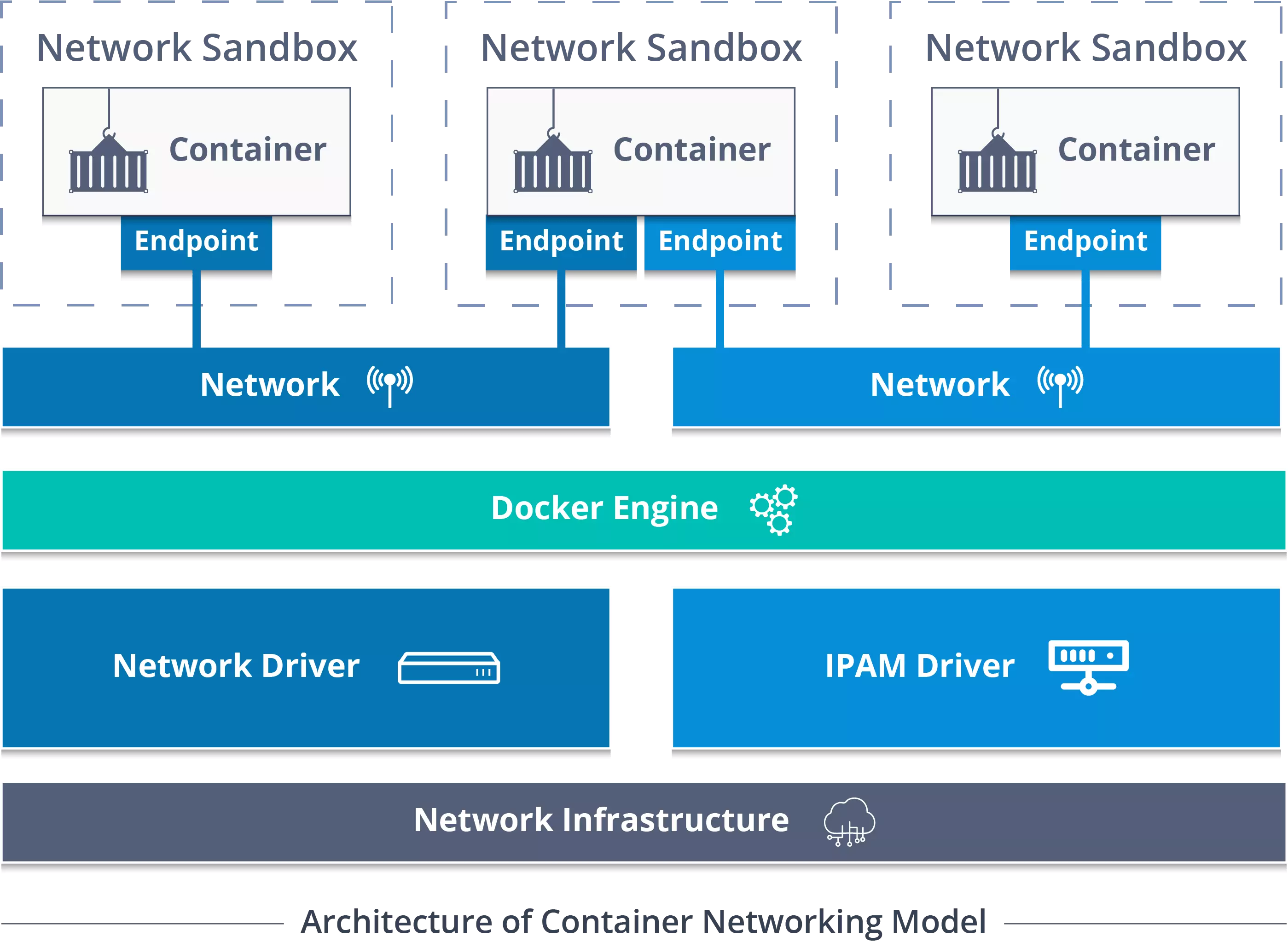
Comunicación entre contenedores usando el motor de Docker. Fuente: Medium
Con todas estas ideas en mente, es evidente que Docker ofrece soluciones fáciles y sencillas para escalar automáticamente aplicaciones alrededor de un clúster de nodos distribuído por el mundo.
Muchas de las aplicaciones de Docker surgen en el mundo DevOps, en donde la mayoría de herramientas de integración continua (CI) y despliegue continuo (CD) han migrado sus infraestructuras hacia Docker. Con esto se consigue que los tests y las compilaciones se hagan de forma sencilla con contenedores de un solo uso.
Otra aplicación directa son las arquitecturas cloud, en donde antes había que configurar cientos de parámetros para desplegar una aplicación web basada en PHP y MySQL y ahora basta con usar uno o varios contenedores que agrupen las funcionalidades que necesitamos.
Por otra parte, gracias a los contenedores los tiempos de desarrollo se han agilizado mucho. Antes, por ejemplo, una aplicación requería de compilar ciertos paquetes y realizar ciertas instalaciones que llevaban mucho tiempo. Con Docker, se exponen las librerías necesarias y se trabaja directamente con aquello que se necesita, sin necesidad de dedicar tiempo a esas tareas.
Docker rules
Desde su nacimiento en 2013 hasta su expansión mundial hace poco más de 4 años, en 2017/18, los contenedores se han convertido en el modus operandi de muchas empresas, que han visto en la tecnología de contenedores una gran ventaja y forma de despegar y aumentar su producción.
Desde entonces, diversos estudios como el llevado a cabo por Portworx cada año brindan la oportunidad de ver qué tecnologías dominan el mercado y cómo va evolucionando el mundo de los contenedores.
De entre los datos obtenidos, es destacable la adopción de contenedores en las empresas tecnológicas: un 87% de los encuestados (2019) afirman usar contenedores en comparación con el 55% registrado en 2017. Es más, el 90% de las aplicaciones que ejecutan en esos contenedores están en entornos de producción, una gran diferencia con 2018 (84%) y 2017 (67%).
Estos datos radican en la inversión económica que las empresas realizan en labores de “contenerización”, invirtiendo entre $500000$ y $1000000$ dólares. De entre todos los motivos que mueven a las empresas a realizar esas inversiones, prima la seguridad de los datos sobre los demás.
Parece ser que una de las principales labores de los contenedores en estas decisiones es la de proteger la información (61%), gestionar las vulnerabilidades fácilmente (43%) y proteger el sistema en tiempo de ejecución (34%). Estos datos van directamente ligados con las medidas de seguridad que las compañías adoptan al usar contenedores:
Cifrar los datos (64%).
Monitorización en tiempo de ejecución (49%).
Escaneo de vulnerabilidades en los registros de contenedores (49%).
Escaneo de vulnerabilidades en las operaciones de CI/CD (49%).
Bloquear anomalías mediante la protección en tiempo de ejecución (48%).
El siguiente motivo de la gran adopción de contenedores es que agiliza mucho la velocidad en el desarrollo y la eficiencia. Por otra parte, la portabilidad de los contenedores permite a las empresas poder mover sus entornos de producción y desarrollo entre una y otra plataforma de nube públicas, de entre las cuales las más usadas (12% de la muestra) son AWS, Azure y Google Cloud.
En particular, se observa cómo AWS (la plataforma de Amazon) es la dominante en este sector, llevándose el 78% del sector; la siguiente, Azure con el 39%; y finalmente, GCP (Google Cloud Platform) con el 35% y subiendo rápidamente. Destaca el crecimiento de Google ya que es quien empezó a invertir mucho dinero en contenedores desde su nacimiento y el creador de Kubernetes, la tecnología de orquestación más usada a nivel mundial.
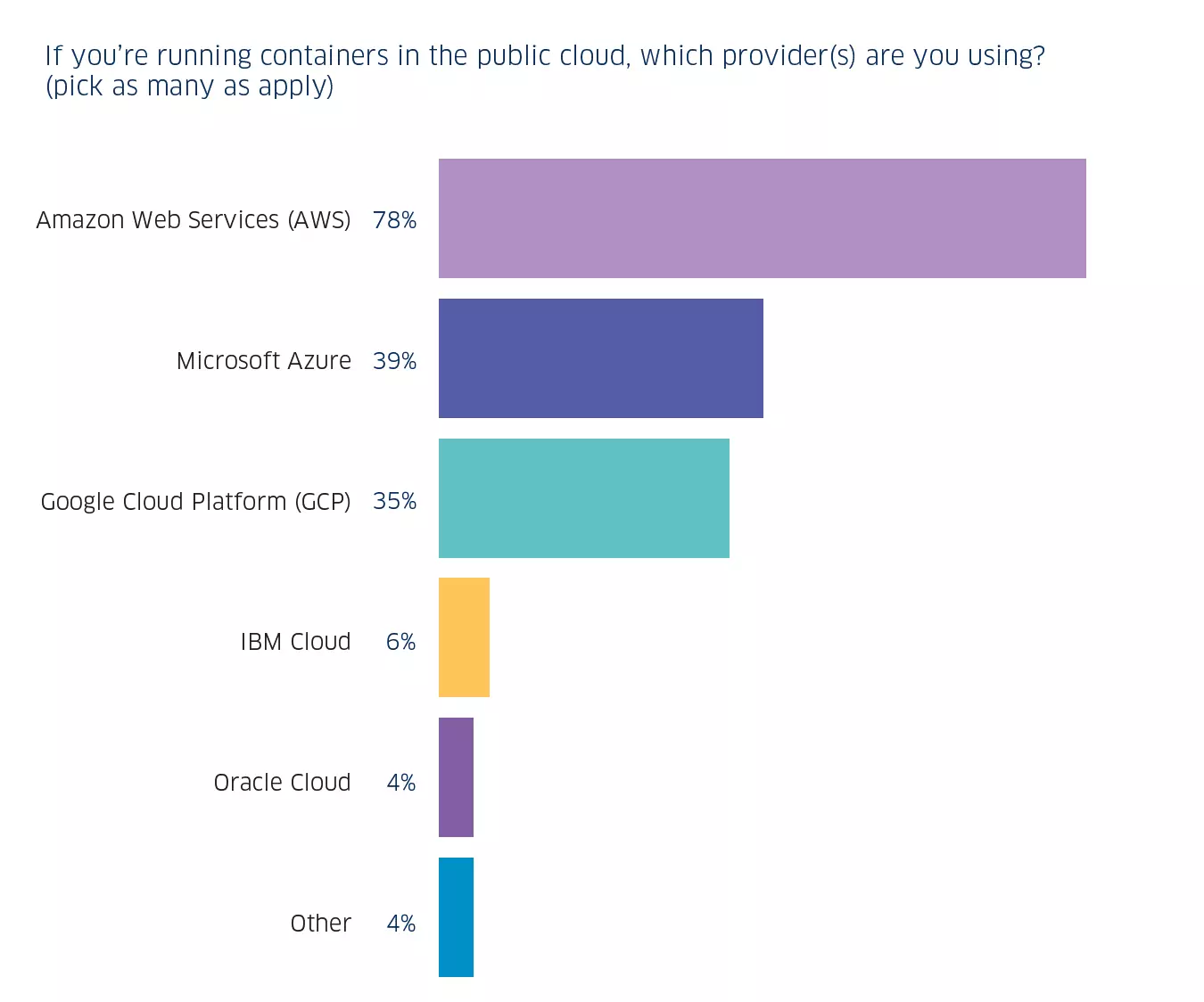
Uso de contenedores según la plataforma cloud. Fuente: StackRox
La situación mencionada anteriormente se ve directamente reflejada en la “contenerización” de aplicaciones en según que plataforma. De los usuarios de Azure, solo el 20% ha creado un contenedor para más de la mitad de sus aplicaciones, significativamente más bajo que el 33% de los no usuarios. Esto se ve drásticamente reducido cuando se hablan de aplicaciones en entorno de producción.
Por el contrario, casi un tercio de los usuarios de GCP (31%) han creado un contenedor para más de la mitad de sus aplicaciones, relativamente superior al 27% de los no usuarios. Este mismo efecto se produce con respecto a las aplicaciones en producción desplegadas en GCP.
Esto se ve reflejado en el siguiente gráfico:
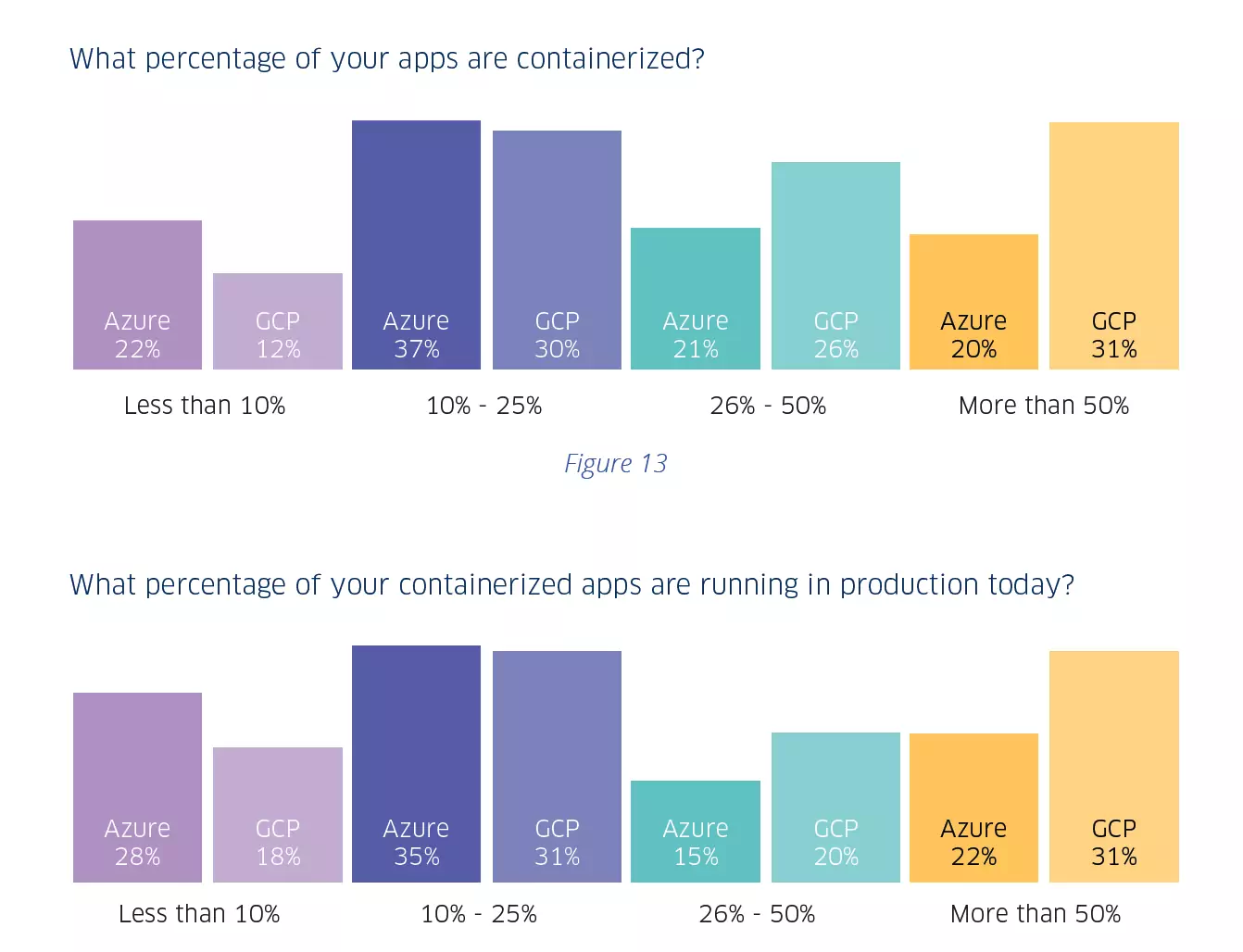
Porcentaje de las aplicaciones desplegadas en contenedores en según qué plataformas. Fuente: StackRox
En un estudio más moderno, se estima en el año 2020 ha supuesto un mayor auge en las tecnologías de “contenerización”, en donde los responsables de IT han priorizado la creación de contenedores para aplicaciones ya existentes, migrar toda la infraestructura a la nube y hacer un mejor uso de las plataformas en la nube. De entre todos los problemas, el principal es cumplir con los requisitos legales, de rendimiento y regulatorios vigentes según las necesidades de la industria; y la portabilidad de las aplicaciones, las cuales estaban confinadas y diseñadas para sistemas en particular y ahora se quieren desplegar en la nube en general.
Esto se ve en la infografía diseñada por Forrester:

Estadísticas de adopción de tecnologías basadas en contenedores en la nube, 2020. Fuente: Capital One
De entre todos los datos anteriores, es destacable el gran uso de Docker y Kubernetes para gestionar toda esta infraestructura. En 2017, Docker representaba un 99% de los contenedores en uso. Sin embargo, con la compra de CoreOS por RedHat y el lanzamiento de la OCI ha promovido el nacimiento y establecimiento de nuevas tecnologías de contenedores que le han quitado cuota de mercado a Docker. Actualmente, la distribución queda:

Usos de tecnologías de contenedores: Docker domina, seguido por rkt y Mesos. Fuente: sysdig
Todo esto nos lleva a ver que si bien aparecen alternativas nuevas Docker sigue siendo la tecnología dominante y la que más adopción está teniendo. Esta competitividad es muy buena ya que permite a Docker y a otras tecnologías de contenedores, como rtk de RedHat (CoreOS), evolucionar, seguir avanzando y mejorando. Lo interesante no es ya usar Docker, rtk o LXC sino que se ha establecido un estándar de contenedores abierto (OCI) y que pone las bases a lo que es una tecnología revolucionaria.
Lecturas recomendadas:
 |  |  |
|---|---|---|
| Luces diurnas reversibles para cualquier coche | Instalar Android 10 (Q) en el Mi A1 | Termius: #1 SSH platform PPA |